Cloud vs On-Premises. To porównanie często pojawia się w artykułach czy na forach branżowych. Jedni twierdzą, że rozwiązania oparte o infrastrukturę On-Premises to przeżytek, inni upierają się, że wciąż to podejście ma swoje zastosowanie. W tym wpisie nie mam zamiaru opowiadać się po żadnej ze stron. W tym artykule chciałbym Ci przedstawić te dwa podejścia na osi czasu. Będzie to artykuł poświęcony ewolucji architektury. Oczywiście jest to tak ogromny temat, że można by mu poświęcić całą książkę. Trzymając się jednak konwencji blogposta postaram się streścić i uprościć temat.
Ewolucja infrastruktury
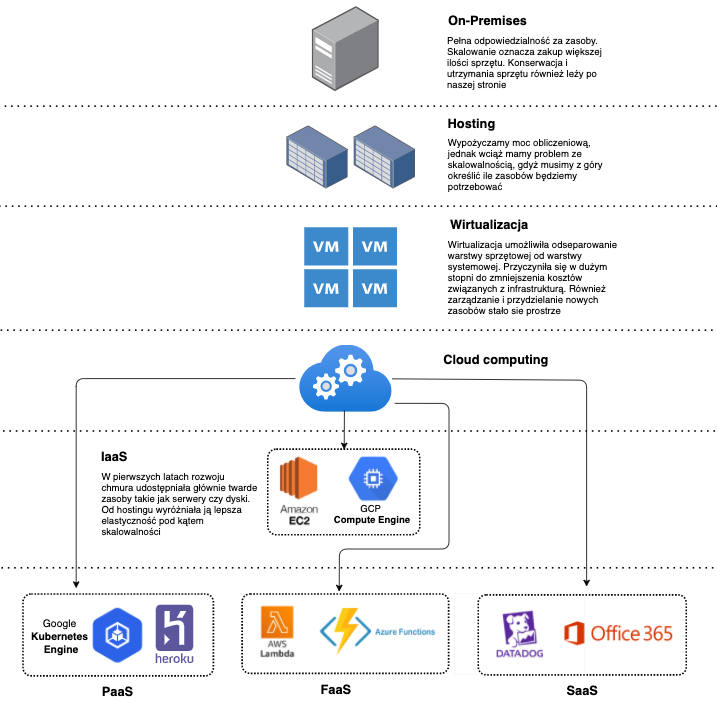
On-Premises
“Na początku był Chaos”. W tym przypadku zaznaczony na górze On-Premise. Starsi ode mnie zapewne lepiej pamiętają te czasy. To co jednak mogliśmy zaobserwować na przestrzeni ostatnich kilkunastu lat to ciągle postępująca ewolucja architektury. Dziś mimo powszechności chmury wciąż jesteśmy w stanie spotkać się z rozwiązaniami opartymi o własne serwerownie. W większości są to systemy legacy, bądź krytyczne usługi, których migracja jest niemożliwa (względy prawne), lub też nieopłacalna. W takim modelu, my jako dostawcy jesteśmy w pełni odpowiedzialni za wszystkie warstwy i aspekty naszego rozwiązania. Począwszy od serwerów, sieć, system operacyjny, kończąc na warstwie aplikacji. Z jednej strony mamy bardzo duża odpowiedzialność, z drugiej strony mamy pełną kontrolę. Kontrolujemy to gdzie fizycznie znajdują się nasze dane oraz kto ma do nich dostęp. Nie martwimy się też o dostępność zewnętrznych dostawców.
Hosting
Hostowanie zasobów był pewnym krokiem ku temu aby przenieść część odpowiedzialności na zewnątrz. W przypadku hostowania outsourcujemy warstwę niskopoziomową, czyli hardware. Zamiast budować własną serwerownie, estymujemy jaki sprzęt będziemy nam potrzebny i podpisujemy umowę z firmą hostingową na dzierżawę ich sprzętu. W tym modelu po naszej stronie wciąż pozostają kwestie systemu operacyjnego (aktualizacje, patchowanie). Hosting nie był jednak remedium na problemy z skalowalnością. O ile zwiększenie przestrzeni dyskowej mogło nie być problemem o tyle zmiana maszyny na mocniejszą owszem. Skalowanie oznaczało wyleasingowanie mocniejszej maszyny a następnie przeprowadzenie migracji. Hostowanie wprowadzało też pewien rodzaj couplingu. Byliśmy bowiem w pewien sposób zależni od dostawcy. Jeśli z jakiegoś powodu serwerownia dostawcy uległa awarii i był niedostępna to tym samym nasze usługi również były nieosiągalne
Wirtualizacja
Kolejny krokiem w ewolucji było rozwój i upowszechnienie wirtualizacji. Wirtualizacja sprawiła, że stało się możliwe oddzielenie systemu operacyjnego i warstwy aplikacyjnej od sprzętu. Dzięki tej technice byliśmy w stanie zastąpić fizyczną infrastrukturę zwirtualizowanymi komponentami. Wirtualizować, inaczej mówiąc symulować możemy niemal wszystko: komponenty sieciowe, serwery, storage, czy stacje robocze ze zdalnym pulpitem. Głównym plusem zastosowania wirtualizacji było obniżenie kosztów. Wcześniej jeden serwer oznaczał dla nas jedną stację roboczą. Za pomocą wirtualizacji mogliśmy jedną maszynę, podzielić na kilka odrębnych hostów. Dzięki temu farmę serwerów mogliśmy zastąpić kilkoma mocniejszymi maszynami w ramach których możliwe było wydzielenie wiele serwerów wirtualnych.
Redukcja wydatków na hardwared jest jednym z głównych plusów wirtualizacji. Innymi istotnymi zaletami jakie przyniosła wirtualizacja były:
- lepsza utylizacja sprzętu.
- łatwiejsze zarządzanie infrastrukturą i przydzielanie nowych zasobów. Prościej jest utworzyć nową maszynę wirtualną niż przyłączyć fizyczny serwer.
- łatwiejsze tworzenie backupów oraz replik serwerów
- zmniejszenie nakładu prac związanych z utrzymywaniem infrastruktury.
Cloud computing
Z wirtualizacji możemy płynnie przejść do chmury. Gdyby nie wirtualizacja nie byłoby chmury – mawiają niektórzy. Faktycznie, aby uprościć sobie ten obraz, możemy przyjąć, że chmura publiczna jest taką gigantyczną serwerownią, w której dostawca poprzez wirtualizację jest w stanie udostępnić dla nas żądane zasoby. Na przykładzie AWS. Gdy potrzebujemy maszyny wirtualnej uruchamiamy serwer EC2. Gdy chcemy utworzyć i skonfigurować sieć, korzystamy z VPC i komponentów z nią związanych (NAT Gateway, Route tables). Gdy potrzebujemy przestrzeń dyskową również mamy do dyspozycji kilka opcji jak EBS bądź EFS. Za wszystkimi tymi usługami nie stoją jednak dedykowane dla nas urządzenia fizyczne. Wszystkie te komponenty są tworzone aplikacyjnie – są wirtualne. Dopiero gdzieś głęboko pod tą warstwą istnieją fizyczne serwerownie cloud providera. W przypadku usług z pod szyldu Serverless, koncepcja jest ten sam (w tym przypadku mamy dodatkową warstwę abstrakcji, która eliminuję konieczność operowania na poziomie wirtualnych serwerów).
Modele udostępniania usług w chmurze
Obecnie każda publiczna chmura w swoim portfolio ma szeroki wachlarz różnego rodzaju usług. Usługi te są świadczone są w różnych modelach. Trzema podstawowymi modelami są:
- IaaS – Infrastructure as a Service
- PaaS – Platform as a Service
- SaaS – Software as a Service

Podstawową różnicą pomiędzy tymi modelami jest zakres odpowiedzialności klienta i dostawcy. W przypadku IaaS dostawca zapewnia nam warstwę infrastruktury (serwery, sieć dyski) w oparciu o wirtualizację. Po jego stronie leży pełna odpowiedzialność za ten sprzęt (patche, aktualizację, konserwacja). W przypadku PasS dostajemy coś więcej poza samą infrastrukturą. Provider udostępnia nam jako usługę platformę, która ma być landing zoonem dla naszej aplikacji. Model SaaS jest modelem najbardziej kompleksowym. W takim przypadku dostajemy od providera gotową do pracy usługę, która po skonfigurowaniu i zasileniu danymi jest gotowa do pracy.


